Допустим, вы хотите построить ЭС в области медицинской диагностики. В этом случае вам вряд ли нужно строить систему, использующую обучение на примерах, потому что имеется большое количество доступной информации, позволяющей непосредственно решать такие проблемы. К сожалению, эта информация приведена в неподходящем для обработки на компьютере виде.
Возьмите медицинскую энциклопедию и найдите в ней статью, например, о гриппе. Вы обнаружите, что в ней приведены все симптомы, причем они бесспорны. Другими словами, при наличии указанных симптомов всегда можно поставить точный диагноз.
Но чтобы использовать информацию, представленную в таком виде, вы должны обследовать пациента, решить, что у него грипп, а потом заглянуть в энциклопедию, чтобы убедиться, что у него соответствующие симптомы. Что-то здесь не так. Ведь необходимо, чтобы вы могли обследовать пациента, решить, какие у него симптомы, а потом по этим симптомам определить, чем он болен. Энциклопедия же, похоже, не позволяет сделать это так, как надо. Нам нужна не болезнь со множеством симптомов, а система, представляющая группу симптомов с последующим названием болезни. Именно это мы сейчас и попробуем сделать.
Идеальной будет такая ситуация, при которой мы сможем в той или иной области предоставить машине в приемлемом для нее виде множество определений, которые она сможет использовать примерно так же, как человек-эксперт. Именно это и пытаются делать такие программы, как PUFF, DENDRAL, PROSPECTOR.
С учетом байесовской системы логического вывода примем, что большая часть информации не является абсолютно точной, а носит вероятностный характер. Итак, начнем программирование:

Полученный формат данных мы будем использовать для хранения симптомов. При слове "симптомы" создается впечатление, что мы связаны исключительно с медициной, хотя речь может идти о чем угодно. Суть в том, что компьютер задает множество вопросов, содержащихся в виде символьных строк <Симптом_1>, <Симптом_2> и т.д.
Например, Симптом_1 может означать строку "Много ли вы кашляете?", или, если вы пытаетесь отремонтировать неисправный автомобиль, — строку "Ослаб ли свет фар?".
Теперь оформим болезни:
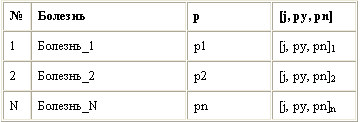
В таком виде мы будем хранить информацию о болезнях. Это не обязательно должны быть болезни — могут быть любые результаты, и каждый оператор содержит один возможный исход и всю информацию, относящуюся к нему.
Поле "болезнь" характеризует название возможного исхода, например "Грипп". Следующее поле — p — это априорная вероятность такого исхода P(H), т.е. вероятность исхода в случае отсутствия дополнительной информации. После этого идет ряд повторяющихся полей из трех элементов. Первый элемент — j — это номер соответствующего симптома (свидетельства, переменной, вопроса, если вы хотите назвать его по-другому). Следующие два элемента — P(E : H) и P(E : не H) — соответственно вероятности получения ответа "Да" на этот вопрос, если возможные исход верен и неверен. Например:

Здесь сказано существует априорная вероятность P(H)=0.01, что любой наугад взятый человек болеет гриппом.
Допустим, программа задает вопрос 1 (симптом 1). Тогда мы имеем P(E : H)=0.9 и P(E : не H)=0.01, а это означает, что если у пациента грипп, то он в девяти случаях из десяти ответит "да" на этот вопрос, а если у него нет гриппа, он ответит "да" лишь в одном случае из ста. Очевидно, ответ "да" подтверждает гипотезы о том, что у него грипп. Ответ "нет" позволяет предположить, что человек гриппом не болеет.
Так же и во второй группе симптомов (2, 1, 0.01). В этом случае P(E : H)=0.9, т.е. если у человека грипп, то этот симптом должен присутствовать. Соответствующий симптом может иметь место и при отсутствии гриппа (P(E : не H)=0.01), но это маловероятно.
Вопрос 3 исключает грипп при ответе "да", потому что P(E : H)=0. Это может быть вопрос вроде такого: "наблюдаете ли вы такой симптом на протяжении большей части жизни?" — или что-нибудь вроде этого.
Нужно подумать, а если вы хотите получить хорошие результаты, то и провести исследование, чтобы установить обоснованные значения для этих вероятностей. И если быть честным, то получение такой информации — вероятно, труднейшая задача, в решении которой компьютер также сможет существенно помочь Вам. Если вы напишите программу общего назначения, ее основой будет теорема Байеса, утверждающая:
P(H : E) = P(E : H) * P(H) / (P(E : H) * P(H) +P(E : не H) * P(не H).
Вероятность осуществления некой гипотезы H при наличии определенных подтверждающих свидетельств Е вычисляется на основе априорной вероятности этой гипотезы без подтверждающих свидетельств и вероятности осуществления свидетельств при условиях, что гипотеза верна или неверна.
Поэтому, возвращаясь к нашим болезням, оказывается:
P(H : E) = py * p / (py * p + pn * (1 - p)) .
В данном случае мы начинаем с того, что Р(Н) = р для всех болезней. Программа задает соответствующий вопрос и в зависимости от ответа вычисляет P(H : E). Ответ "да" подтверждает вышеуказанные расчеты, ответ "нет" тоже, но с (1 – py) вместо py и (1 – pn) вместо pn. Сделав так, мы забываем об этом, за исключением того, что априорная вероятность P(H) заменяется на P(H : E). Затем продолжается выполнение программы, но с учетом постоянной коррекции значения P(H) по мере поступления новой информации.
Описывая алгоритм, мы можем разделить программу на несколько частей.
Часть 1.
Ввод данных.
Часть 2.
Просмотр данных на предмет нахождения априорной вероятности P(H). Программа вырабатывает некоторые значения массива правил и размещает их в массиве RULEVALUE. Это делается для того, чтобы определить, какие вопросы (симптомы) являются самыми важными, и выяснить, о чем спрашивать в первую очередь. Если вы вычислите для каждого вопроса RULEVALUE[I] = RULEVALUE[I] + ABS (P(H : E) – P(H : не E)), то получите значения возможных изменений вероятностей всех болезней, к которым они относятся.
Часть 3.
Программа находит самый важный вопрос и задает его. Существует ряд вариантов, что делать с ответом: вы можете просто сказать: "да" или "нет". Можете попробовать сказать "не знаю", — изменений при этом не произойдет. Гораздо сложнее использовать шкалу от –5 до +5, чтобы выразить степень уверенности в ответе.
Часть 4.
Априорные вероятности заменяются новыми значениями при получении новых подтверждающих свидетельств.
Часть 5.
Подсчитываются новые значения правил. Определяются также минимальное и максимальное значения для каждой болезни, основанные на существующих в данный момент априорных вероятностях и предположениях, что оставшиеся свидетельства будут говорить в пользу гипотезы или противоречить ей. Важно выяснить: стоит ли данную гипотезу продолжать рассматривать или нет? Гипотезы, которые не имеют смысла, просто отбрасываются. Те же из них, чьи минимальные значения выше определенного уровня, могут считаться возможными исходами. После этого возвращаемся к части 3.
Составные части системы экспертных консультаций. В любой системе экспертных консультаций обязательно должны иметься следующие три компоненты:
1) язык представления знаний, с помощью которого можно интуитивно представить знания о сложной области;
2) стратегия, решения задач, позволяющая выполнять действия с представленными знаниями столь же компетентно и умело, как это делают эксперты-люди;
3) интерфейс с пользователем, обеспечивающий естественность и удобство доступа к знаниям, которыми обладает программа, и способный объяснить свои ответы как неопытным пользователям, так и пользователям-экспертам.
Пролог пригоден для разработки систем экспертных консультаций, поскольку в нем имеются и язык представления знаний (Фразы Хорна), и общецелевая стратегия решения задач, основанная на принципе резолюций.
Интерфейс с пользователем. Важной особенностью интерфейсов с пользователем многих систем экспертных консультаций является их способность объяснить, как были найдены ответы. Это свойство необходимо доя того, чтобы пользователи программы прониклись к ней доверием. Если такое объяснение не будет обеспечиваться, то у пользователей не будет оснований считать ответы экспертной системы достоверными. Ответ можно пояснить путем отображения цепочки выводов, выполненных программой при поиске ответа.
Стратегия решения задач. В интерпретаторе Пролога применяется стратегия решения задач с обратным ходом решения: он начинает свою работу с цели и продвигаемся назад до тех пор, нока не встретит факты. В некоторых других системах решения задач (например, в системе, реализующей язык OPS-5) принята стратегия с прямым, ходом решения. Некоторые задачи могут быть решены более изящно при помощи стратегии с прямым ходом решения (к примеру, решение уравнений или грамматический разбор языков, содержащих леворекурсивные конструкции, скажем, японского языка).
Подробное объяснение стратегии решения задач, принятой в интерпретаторе языка Пролог, было дано ранее. Процедура "вып", рассматриваемая далее, в точности моделирует эту стратегию решения задач. Поэтому можно трактовать процедуру "вып" как реализацию Пролога, написанную на самом Прологе. |
 Главная
Главная Каталог файлов
Каталог файлов






