Поиск в массиве записей может быть выполнен значительно быстрее, если они предварительно отсортированы по значению ключей, которые используются для поиска.
Пусть исходный массив записей a1,a2,…,an отсортирован таким образом, что значения ключей: f(a1) ≤ f(a2) ≤ … ≤ f(an). Тогда бинарный поиск выполняется следующим образом: Пусть k – аргумент поиска, тогда:
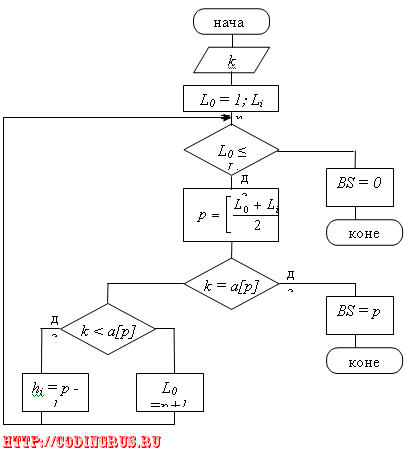
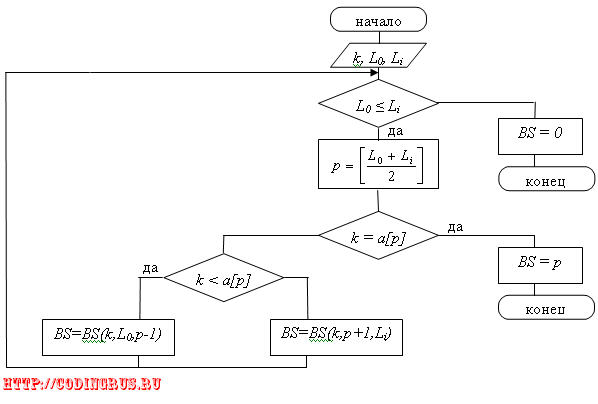
1) На первом шаге вычисляется индекс среднего элемента
p=n/2
Если значение p получается не целым, то оно может округляться в любую сторону (но всегда в одну).
2) Если k = f(ap), то – конец алгоритма. Результатом будет индекс элемента p этого массива.
3) Если это условие не выполняется, то проверяется следующее условие: k < f(ap). При его выполнении поиск должен быть продолжен в левой половине массива, т.е. среди элементов: a1,a2,…,ap-1. В противном случае, т.е. при k > f(ap) поиск должен быть продолжен в другой половине, т.е.: ap+1,ap+2,…,an.
В выбранной половине опять определяется средний элемент, и процедура повторяется до тех пор, пока не встретится запись с заданным ключом или пока не останется один не просмотренный элемент. Если этот элемент имеет ключ k, то процесс завершился успешно, если нет, то запись с заданным ключом отсутствует.
Каждый шаг бинарного поиска требует два сравнения ключей: k = f(ap) и k < f(ap). Каждый шаг уменьшает зону поиска примерно в два раза. Поэтому один не просмотренный элемент останется через Log2n шагов. Поскольку на каждом требуется два сравнения, то в худшем случае бинарный поиск требует не более чем E = 2Log2n + 1 сравнений.
По сравнению с линейным поиском считается, что бинарный поиск становится более эффективным, когда n > 20.
Основным недостатком бинарного поиска является необходимость хранения записей в отсортированном виде, что практически невозможно при частых вставках и удалениях элементов в списке. Реализация: 1) Нерекурсивный вариант:
k – ключ записи
a[1..n] – массив записей
L0, Li – переменные, ограничивающие зону поиска
BS = 0 – запись с заданным ключом отсутствует
BS 2) Рекурсивный вариант.
В рекурсивном варианте будем считать, что алгоритм бинарного поиска реализуется функцией BS (k, L0, Li), k – аргумент поиска, L0, Li – верхняя и нижняя границы поиска.
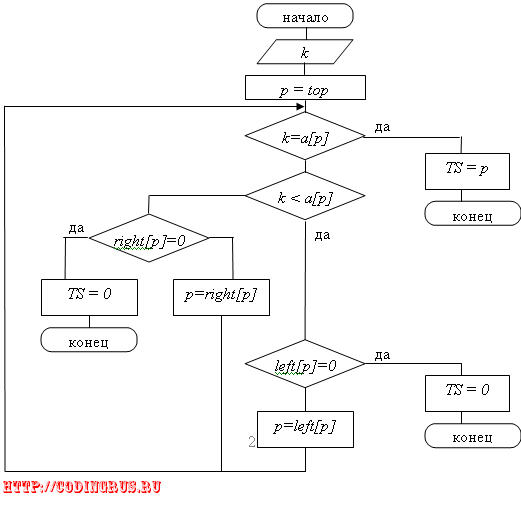
Поиск по бинарному дереву:
Использование бинарного дерева для организации поиска позволяет сохранить эффективность на уровне бинарного поиска, обеспечивая при этом достаточно простую реализацию вставки и удаления элемента. Для выполнения поиска бинарное дерево стоится следующим образом (предполагается, что никакие две записи не имеют одинаковых ключей):
1) Первую запись входной последовательности сопоставляют с корнем дерева.
2) Для каждой следующей записи ключ сначала сравнивается с ключом корня. Если он меньше чем ключ корня, то далее сравнивается с ключом правого потомка и т.д. до тех пор, пока потомок не будет отсутствовать. Место этого отсутствующего потомка занимает новая вершина, которой сопоставляется очередная запись.
Шаг 2 повторяется до тех пор, пока не будет просмотрена вся входная последовательность записей. Поиск записи с заданным ключом осуществляется в точности по рассматриваемой процедуре. Сложность алгоритма поиска по дереву определяется высотой дерева и колеблется в пределах от O(Log2n) до O(n).
Реализация:
k – ключ поиска
p – индекс некоторой вершины
a[p] – значение ключа для этой вершины
left[p] – номер левого потомка вершины p, если p=0, то потомок отсутствует
right[p] – номер левого потомка вершины p
top – номер вершины, которая является корнем дерева
TS = номеру вершины – в случае успешного поиска
TS = 0 – в случае неуспешного поиска
Опубликовал Kest
January 29 2010 21:23:10 ·
1 Комментариев ·
26357 Прочтений ·
• Не нашли ответ на свой вопрос? Тогда задайте вопрос в комментариях или на форуме! •
Комментарии
Папа December 27 2011 07:13:37
:(
Добавить комментарий
Рейтинги
Рейтинг доступен только для пользователей.
Пожалуйста, залогиньтесь или зарегистрируйтесь для голосования.
Нет данных для оценки.
Гость
Вы не зарегистрированны? Нажмите здесь для регистрации.
 Главная
Главная Каталог файлов
Каталог файлов