Для представления арифметических и логических выражений часто используется польская запись, которая просто и однозначно указывает порядок выполнения операций. Кроме того, она не требует использования скобок. В этой записи операторы следуют непосредственно за своими операндами.
Основные свойства польской записи: идентификаторы следуют в том же порядке, что и в инфиксной записи; операторы записываются слева направо в порядке, как они должны выполняться; операторы располагаются непосредственно за своими операндами. Польскую запись можно расширить на случай операторов с одним операндом. Это унарные операторы (отрицание, сдвиг и т.д.).
<операнд>::=<идентификатор>|<константа>|<операнд><операнд> <бинарный оператор>|<операнд><унарный оператор>
<бинарный оператор>::= + | - | * | / | …
<унарный оператор>::= not | # | …
Для бинарных операций удобной формой записи являются тетрады (<оператор>, <операнд 1> , <операнд 2> , <результат>)
Например выражение ABC+* можно представить в виде:
(1) (+, B, C, T1)
(2) (*, A, T1, T2),
где T1, T2 – временные переменные, создаваемые транслятором.
Важно отметить, что тетрады располагаются в том порядке, в котором они должны выполняться.
Унарные операторы также оформляются в виде списка тетрад, в которых <операнд 2> остается пустым. Например, (– , А, , Т1).
Характеристика алгоритма
Выражение, представленное в польской записи, можно вычислить за один просмотр слева направо. При этом для хранения операндов используется стек. Алгоритм вычисления представляется в следующем виде:
1. Если анализируемый символ является идентификатором или константой, то его значение помещается в стек и осуществляется переход к следующему символу. Это соответствует использованию правила <операнд> ::= <идентификатор>.
2. Если сканируемый символ – бинарный оператор, то он применяется к двум верхним операндам в стеке, а результат снова помещается в стек. С точки зрения семантики это эквивалентно использованию правила <операнд> ::= <операнд> <операнд> <оператор>.
3. Если сканируемый символ – унарный оператор, то он применяется к верхнему элементу стека, который затем заменяется на результат, что описывается правилом <операнд> ::= <операнд> <оператор>. После просмотра цепочки польской записи полученное значение выражения остается в стеке. Процесс вычисления для строки AB@CD*-+ показан в таблице 1, где Т1, Т2, Т3 – промежуточные результаты, а Т4 – значение выражения.
Табл.1
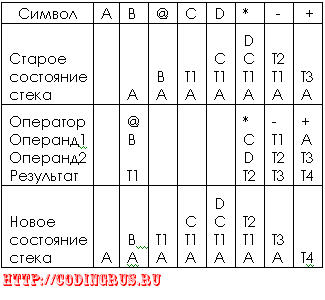
Описанный алгоритм используют для формирования списка тетрад. В этом случае в стек помещаются не числовые значения, а имена идентификаторов, констант и временных переменных. Список тетрад для рассмотренного примера приведен ниже:
(1) (@, В, , Т1)
(2) (*, С, D, T2)
(3) (-, T1, T2, T3)
(4) (+, A, T3,T4)
|
 Главная
Главная Каталог файлов
Каталог файлов





