Оперативный анализ данных
При разработке информационных систем поддержки принятия решений руководителей приходится решать проблему выполнения оперативного анализа данных. Под оперативным анализом понимают быстрое выполнение сложных запросов на выборку данных с группировкой по нескольким полям и вычислением агрегатных функций. Обычно на выполнение таких запросов отводятся доли или единицы секунды. При использовании обычных реляционных БД удовлетворительно решить подобные задачи не представляется возможным. Для решения данной проблемы используют специальную технологию под названием OLAP (Online Analysis Processing). Технология предполагает построение так называемых кубов решений, с помощью которых можно быстро получать необходимую для анализа информацию.
OLAP-компоненты Borland Delphi
В Borland Delphi имеется специальный набор OLAP компонентов, расположенных на вкладке Decision Cube (куб решений). Некоторые из этих компонентов похожи на уже знакомые вам компоненты на вкладках Data Access и Data Controls. Рассмотрим назначение OLAP компонентов.
• TDecisionQuery – невизуальный компонент для организации SQL запросов к БД, на основании результатов которых строится гиперкуб. Аналог компонента TADOQuery. Вполне допустимо использовать и обычный компонент TADOQuery, однако текст запросов придется писать вручную, в то время как TDecisionQuery обладает специальным редактором для построения запросов.
• TDecisionCube – невизуальный компонент для построения гиперкуба.
• TDecisionSource – невизуальный компонент источника данных из гиперкуба. Аналог компонента TDataSource.
• TDecisionPivot – визуальный компонент для выбора и настройки требуемого сечения гиперкуба.
• TDecisionGrid – визуальный компонент для отображения сечения гиперкуба. Аналог компонента TDBGrid .
• TDecisionGraph – визуальный компонент для отображения диаграммы на основании данных из сечения гиперкуба. Аналог компонента TDBChart.
Рассмотрим возможности технологии OLAP на следующем примере:
БД хранит сведения о продажах автомобилей некоторой фирмой. Необходимо выполнить анализ количества продаж различных марок автомобилей в разные месяцы различными продавцами.
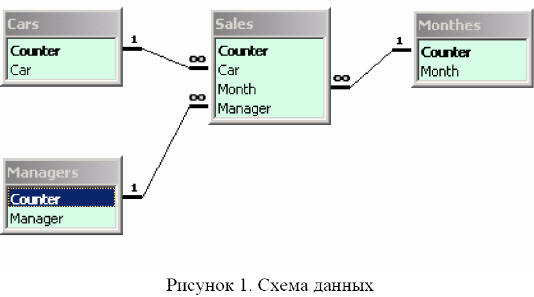
БД, для которой выполняется оперативный анализ должна иметь звездообразную структуру. Т.е. должно быть несколько таблиц-справочников и одна подчиненная для всех таблица. В соответствии с этим принципом БД состоит из следующих таблиц:
Cars – автомобили. Хранятся сведения о марках автомобилей, продаваемых фирмой, в данном случае – название марки и внутренний для БД код.
Months – месяцы. Хранятся сведения о месяцах, в которые осуществлялись продажи: название месяца и его порядковый номер.
Managers – Продавцы. Хранятся сведения о сотрудниках фирмы, осуществлявших продажи. В данном случае фамилия сотрудника и внутренний для БД код.
Sales – продажи. Хранятся сведения о фактах продаж, в данном случае модель автомобиля, месяц и сотрудник, а также внутренний для БД номер факта продажи. Эта таблица является подчиненной для всех остальных таблиц.
Схема данных изображена на рисунке ниже.
С точки зрения анализа, необходимо выбрать в подчиненной таблице:
• поля, являющиеся измерениями, т.е. ребрами гиперкуба;
• целевые функции, т.е. поля или выражения на основе полей подчиненной таблицы, значения которых будут хранится внутри гиперкуба.
В нашем примере целевой функцией будет являться количество продаж (COUNT(Sales.Counter)), а измерениями – марка автомобиля (Sales.Car), месяц (Sales.Months) и продавец (Sales.Manager). Другими словами, количество продаж есть функция от трех переменных: марки автомобиля, месяца и продавца.
Порядок создания клиентского приложения для выполнения оперативного анализа следующий:
1. Создадим БД со схемой, указанной на рисунке 1.
2. Разместим на главной форме следующие компоненты:
• TADOConnection, имя – ADOConnection;
• TADOQuery, имя – ADOQuery;
• TDecisionCube, имя – DecisionCube;
• TDecisionSource, имя – DecisionSource;
• TDecisionPivot, имя – DecisionPivot;
• TDecisionGrid, имя – DecisionGrid.
3. Зададим следующие свойства компонентов:
DecisionGrid.DecisionSource := DecisionSource;
DecisionPivot.DecisionSource := DecisionSource;
DecisionSource.DecisionCube := DecisionCube;
DecisionCube.DataSet := ADOQuery;
ADOQuery.Connection := ADOConnection;
Настроим соединение компонента ADOConnection с БД.
4. Подготовим текст запроса для формирования набора данных, из которого будет строиться гиперкуб, и поместим его в свойство SQL компонента ADOQuery:
SELECT Cars.Car, Managers.Manager, Monthes.Months,
COUNT(Sales.Counter)
FROM ((Sales
INNER JOIN Cars
ON (Sales.Car = Cars.Counter))
INNER JOIN Managers
ON (Sales.Manager = Managers.Counter))
INNER JOIN Monthes
ON (Sales.Months = Monthes.Counter)
GROUP BY Cars.Car, Managers.Manager, Monthes.Months
В предложении SELECT указывают все поля измерений и целевых функций (функций может быть несколько). В предложении FROM указывают таблицу или табличное выражение, из которых строится гиперкуб. В нашем случае мы связываем все четыре таблицы, чтобы значениями измерений стали не числовые значения кодов автомобилей, месяцев или продавцов, а их символьные значения. Таким образом, мы подгружаем из таблиц-справочников названия автомобилей и месяцев, а также фамилии продавцов. В предложении GROUP BY перечисляют все поля измерений, причем точно в том же порядке и количестве, как они были записаны в предложении SELECT.
Активизируем компонент ADOQuery.
6. Двойным щелчком по компоненту DecisionCube откроем специализированный редактор для настройки свойств куба. Здесь нас может заинтересовать задание русских имен для измерений вместо их изначальных латинских названий, взятых из названий соответствующих полей:
Car* Автомобиль
Manager* Продавец
Months* Месяц
Expr1003* Количество продаж
Кроме того, здесь можно подсчитать размер куба в ячейках, ограничить максимальное количество измерений и максимальный размер куба и др.
7. В результате получим уже на этапе разработки приложения возможность строить различные сечения гиперкуба. Запустим приложение и проведем анализ данных. Главное окно полученного приложения показано на рисунке ниже.
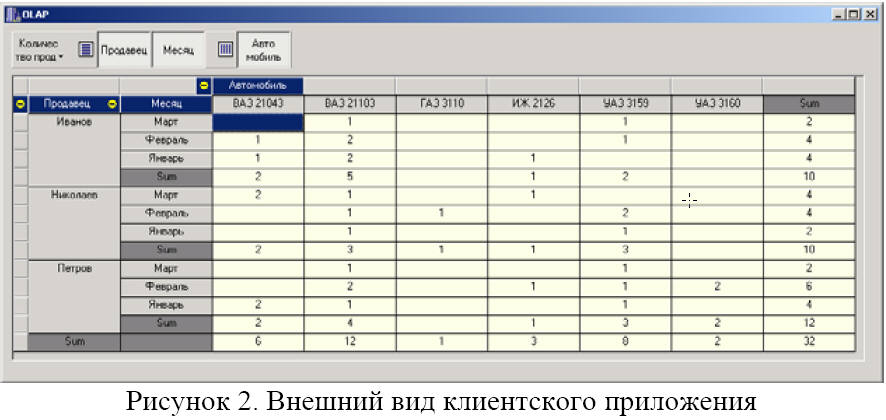
С помощью компонента TDecisionPivot (рисунок 3) можно выбрать одну из определенных ранее целевых функций (кнопка 1). Кроме того, можно выбрать требуемые измерения для построения сечения гиперкуба (кнопки Продавец, Месяц и Автомобиль). Измерения можно включить или отключить, нажимая соответствующую кнопку.
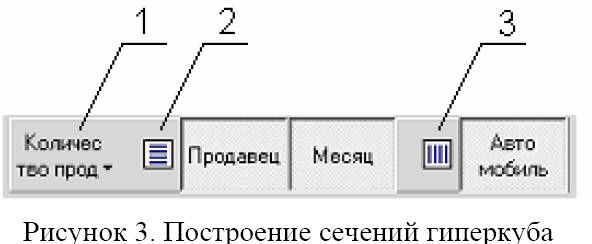
Измерения могут быть использованы в качестве названий строк или названий столбцов. В первом случае кнопку соответствующего измерения перетаскивают к пиктограмме 2, во втором случае – к пиктограмме 3. Например, на рис.3 измерения Продавец и Месяц располагаются по строкам, а измерение Автомобиль – по столбцам.
На внешний вид сечения также влияет порядок расположения кнопок соответствующих измерений. Так, на рисунке 3, сначала следует измерение Продавец, а затем измерение Месяц. В результате на рисунке 2 можно наблюдать группировку строк сначала по продавцам, а затем по месяцам.
В некоторых случаях при компиляции или запуска приложения, использующего компоненты Decision Cube, может несколько раз появиться диалоговое окно с предложением установить ряд компонентов в системе. В рамках решения учебных задач следует игнорировать установку, нажав кнопку Отмена.
|
 Главная
Главная Каталог файлов
Каталог файлов





